Image Compression is an exciting field, with applications for light-weight and mobile computing. Deep Learning, especially representation learning methods, helps to abstract features in an image into simpler and smaller representations. In this project, I work with learning how to reconstruct mammographic images using representation learning.
Autoencoders and Variational Autoencoders (VAEs)
Autoencoders and VAEs learn small latent representations of images that we can use to compress images and then reconstruct them when we need them. Autoencoders and VAEs differ in the following ways:
| Autoencoders | VAEs | Both |
|---|---|---|
| Learn a small representation by minimizing reconstruction loss. | Learn how to sample from a distribution that is close to the original image distribution. | Learn a low-dimensional representation of the data. |
| This Is a generative model that can be used to create synthetic data. | Decoders can recreate a higher-dimension image | |
| Include a KL-divergence loss for optimizing the sampling step. | Unsupervised Learning |
Comparing the Reconstruction Errors
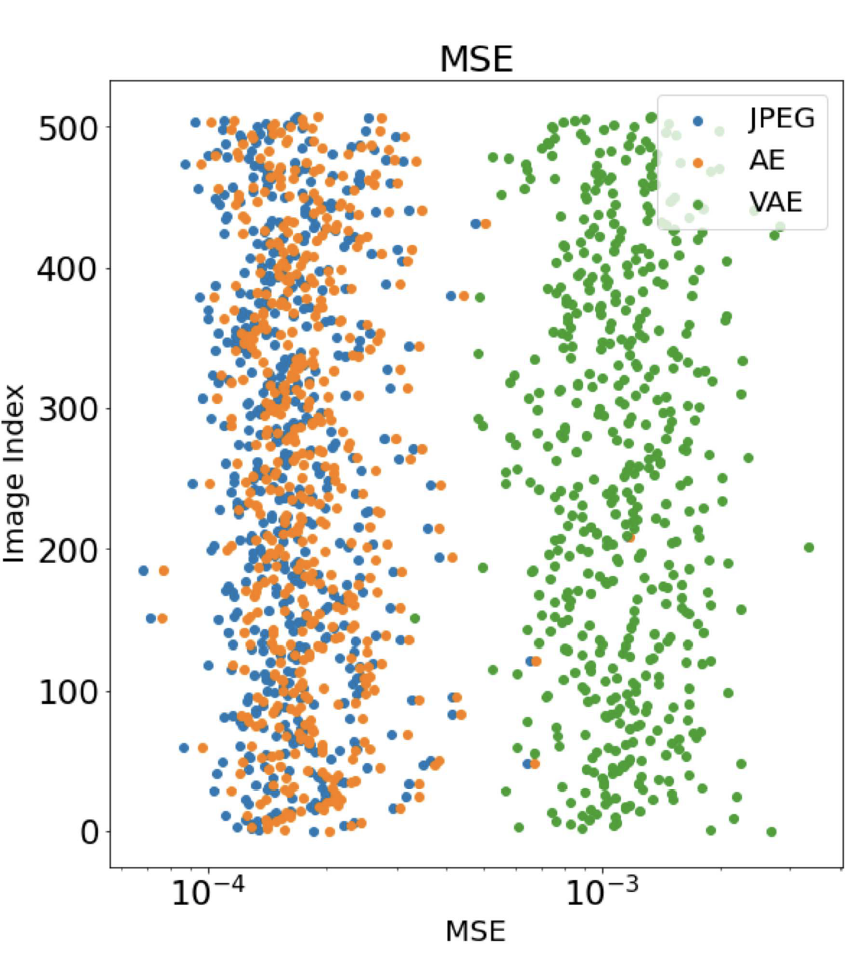
The Autoencoder is very close to the JPEG baseline, as it primarily focuses on minimizing the reconstruction loss. Because the Variational Autoencoder learns an optimized distribution to learn the representation then. A good discussion on this is found in the Stanford CS231n Lecture Notes; it varies significantly from the baseline and has a significantly higher error!
You can see the qualitative error results below:
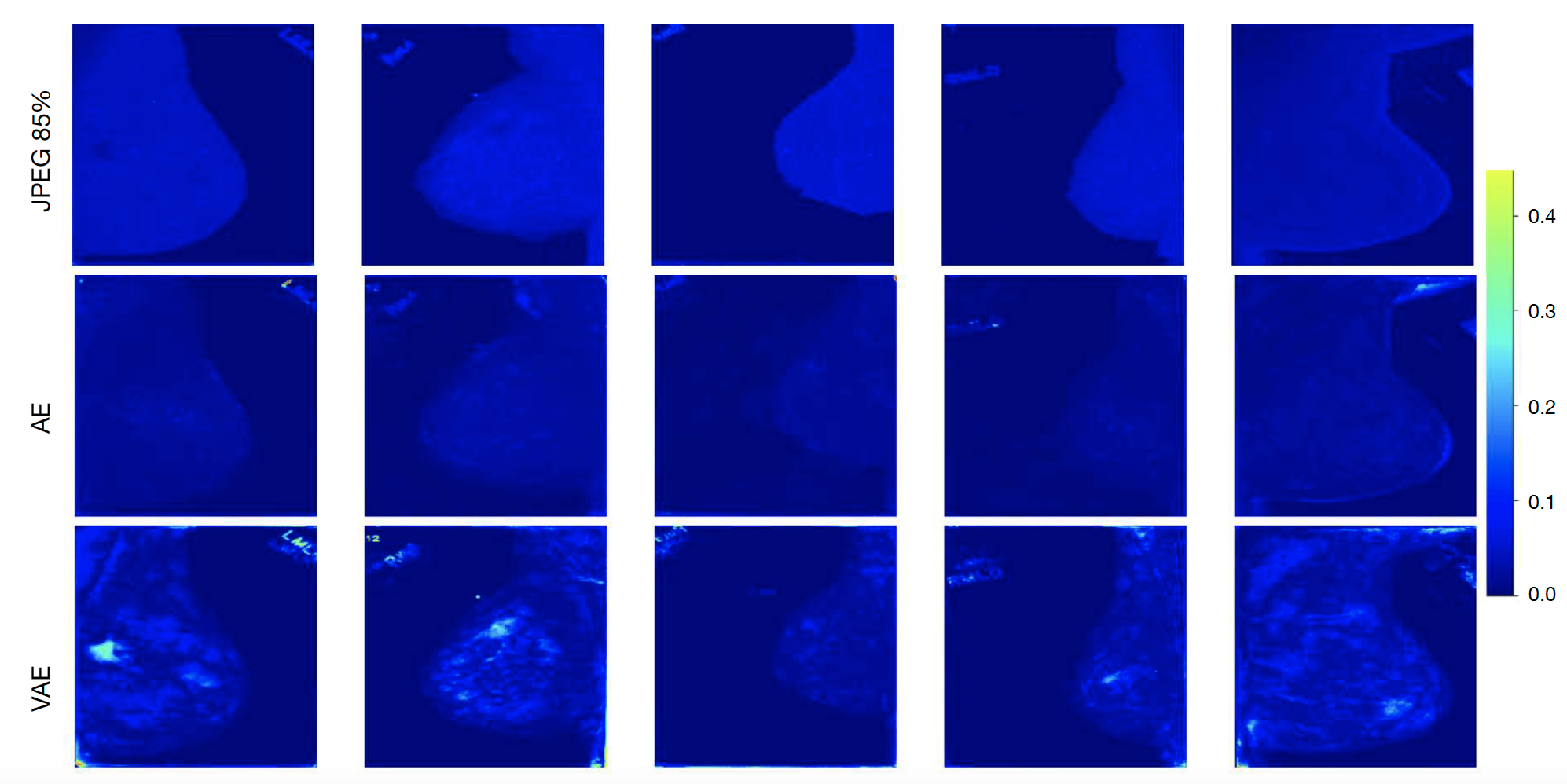
Brighter colors mean higher error, as compared to darker colors.
Final Thoughts
Overall, I learned a lot throughout this project, and I now see image compression as a fundamental concept for storing data efficiently. By compressing images, we can free up computers and mobile devices for other challenging and complex tasks!