By far, the industry standards for Machine Learning are TensorFlow, Python, and RapidMiner. RapidMiner is the most intuitive to use so will be shown here.
RapidMiner consists of nodes that act as functions and edges that act as flow of information.
Download a free version of RapidMiner here.
Here is an example workflow:
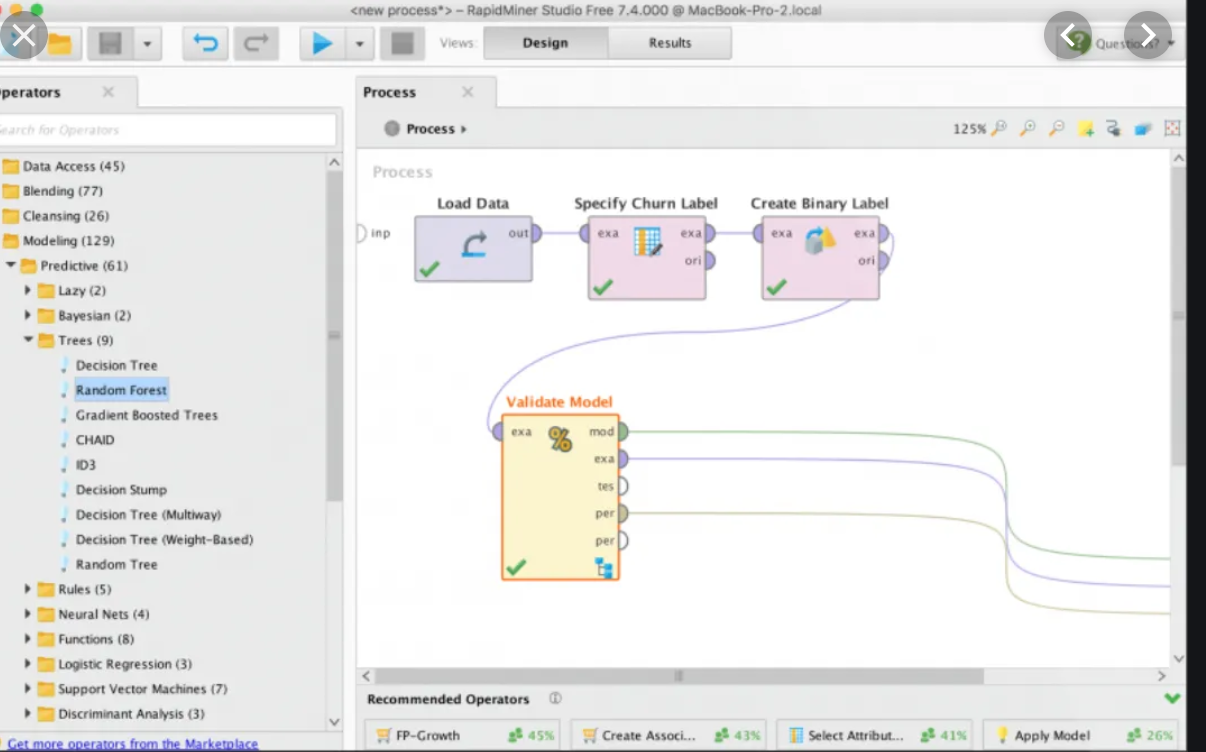
Data can be uploaded using the “Load Data” node. Different nodes than perform different algorithms/transformations using the data.
Here is an example workflow for the Machine Learning split-validation tests used for the PEX Aqueous Humor Experiments:
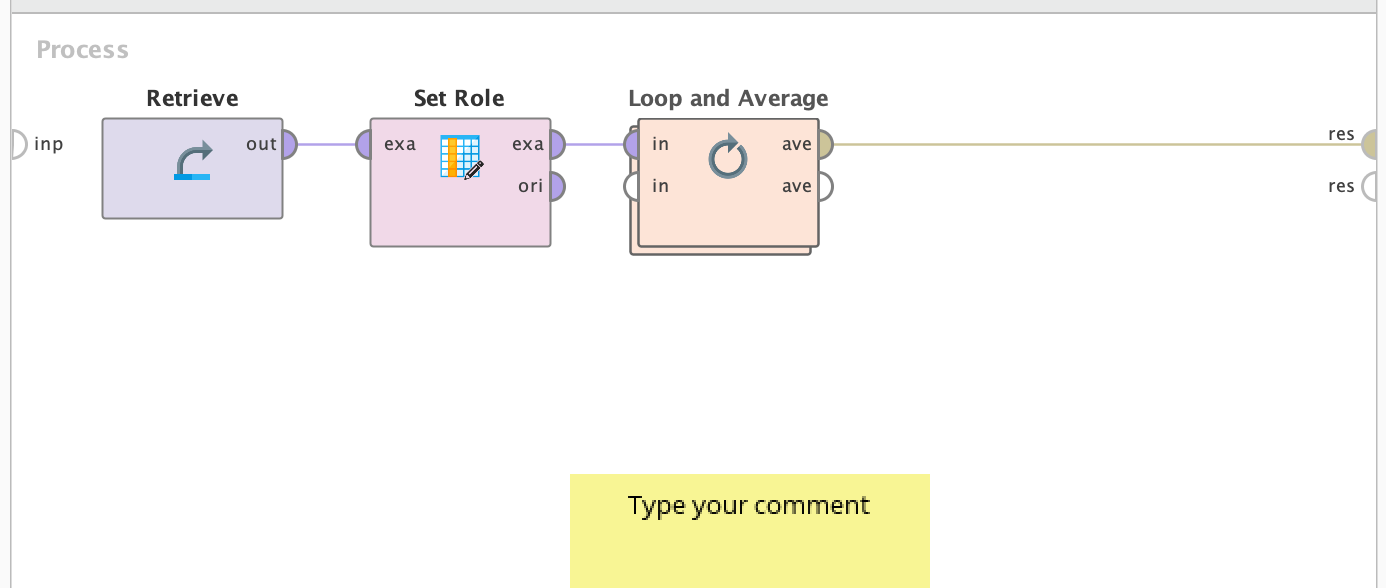
First Layer
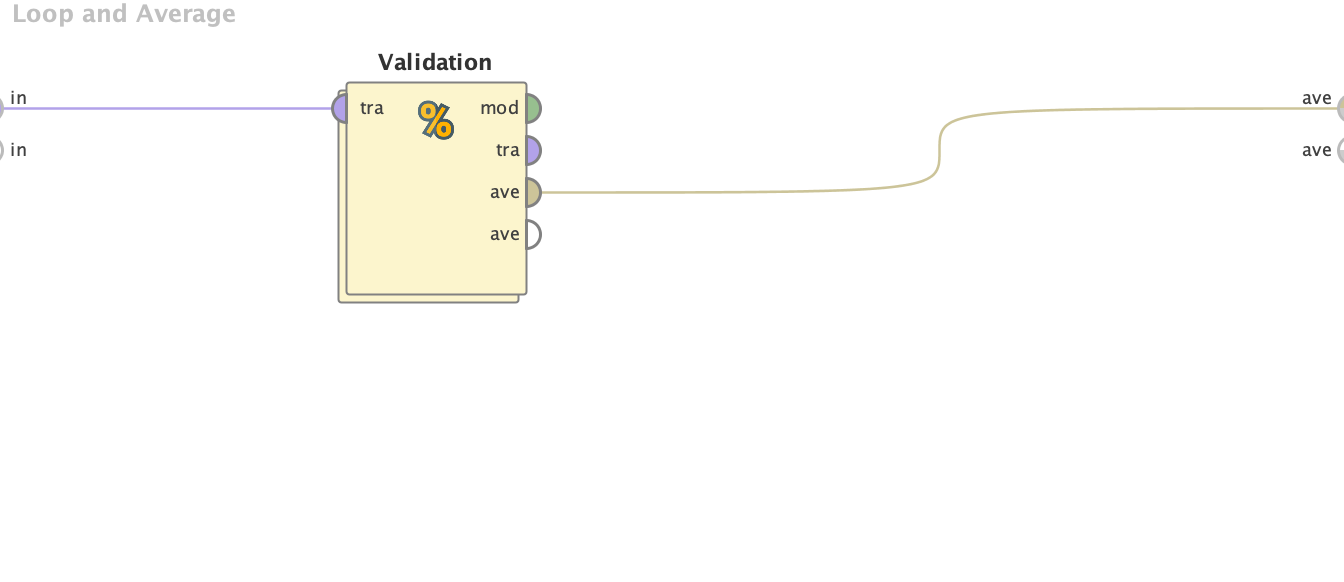
Second Layer
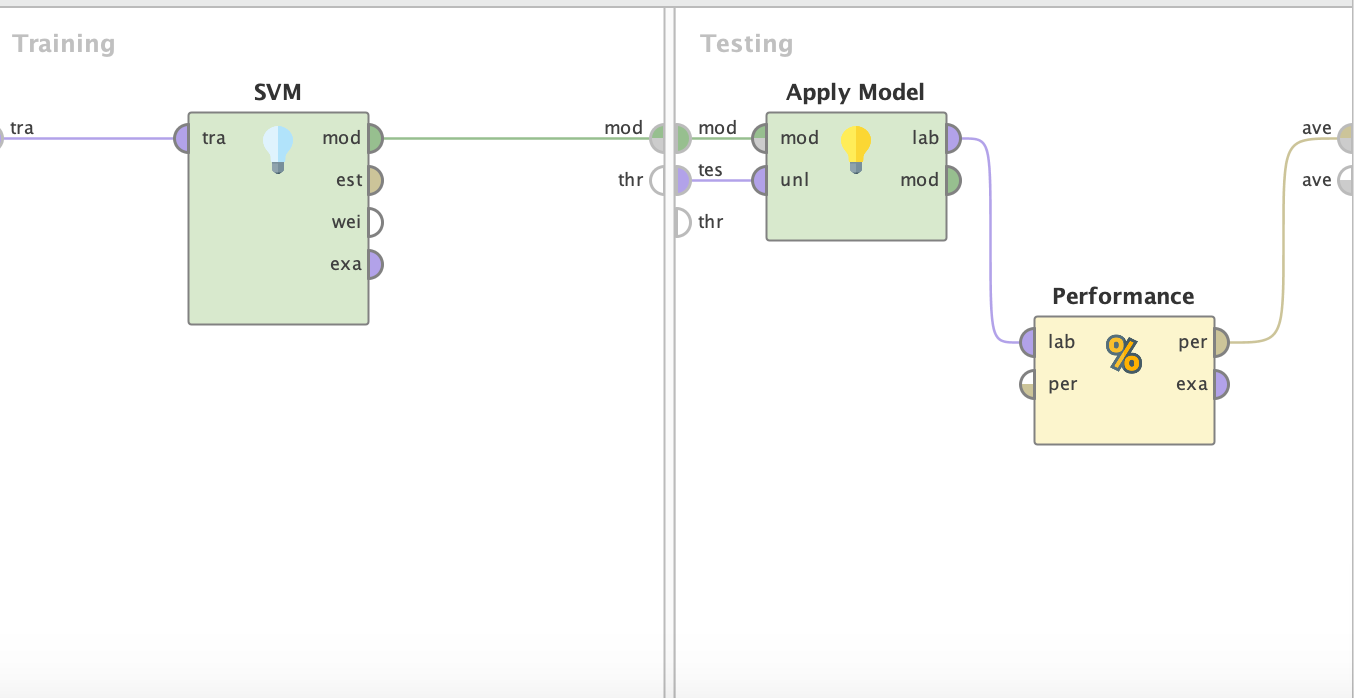
Each layer represents a distinct subprocess.
Layer 1: Extract data. Set role such that the class column is set as “Label”. Loop and average the performance results after performing multiple test runs. Layer 2: Split Validation. The parameters can be changed to indicate the ratio of data used to train/test Layer 3: Applying the model and recording performance.
RapidMiner documentation is often very useful for figuring out the use of each node and can be found here